20190320-每周刷题
1. Python和Java、PHP、C、C#、C++等其他语言的对比?
2. 简述解释型和编译型编程语言?3. 代码中要修改不可变数据会出现什么问题 抛出什么异常4. print 调用 Python 中底层的什么方法5. 简述你对 input()函数的理解6. Python解释器种类以及特点?7. Python2 中 range 和 xrange 的区别8. 位和字节的关系?9. b、B、KB、MB、GB 的关系?10. 请至少列举5个 PEP8 规范(越多越好)。11. python递归的最大层数?递归函数停止的条件12. ascii、unicode、utf-8、gbk 区别?13. 字节码和机器码的区别?14. 三元运算规则以及应用场景?15. 列举 Python2和Python3的区别?1. Python和Java、PHP、C、C#、C++等其他语言的对比?
C、C++、C# 都是编译性语言,Python是一门解释型的动态类型的语言,在python中,对象是通过引用传递的,编写代码时不需要声明变量类型,直接给变量赋值即可。python是一边编译一边执行的,所以相较于C语言和Java来说运行速度会比较慢,但肉眼几乎感知不到。Python本身就是由C语言开发出来的,而且是开源的。
Java:具有卓越的通用性、高效性、平台移植性和安全性,容易学,学精难,工具丰富 ,大多数人在用。缺点:运行速度相对于C/C++有些缓慢了,这是机制原因导致的。适用于网页、企业级开发、普通应用软件、游戏后台。
PHP:跨平台,性能优越;语法简单,入门快;目前主流技术都支持;有比较完整的支持;有很多成熟的框架;PHP 5已经有成熟的面向对象体系,能够适应基本的面向对象要求;有成熟的社区来支持PHP的开发;目前已经很多大型应用都是使用PHP;有很多开源的框架或开源的系统可以使用;配置及部署相对简单一些。缺点:多线程支持不太好,大多数时候我们只能简单的模拟去实现的;对语法不太严谨;PHP的解释运行机制繁琐。适用于网络前端,用于生成网页。也可以整个web服务器都用php,比如很多论坛引擎。
C:简洁紧凑、灵活方便;运算符丰富;数据类型丰富;表达方式灵活实用;允许直接访问物理地址,对硬件进行操作;生成目标代码质量高,程序执行效率高;可移植性好;表达力强;缺点:C语言的缺点主要表现在数据的封装性上,这一点使得C在数据的安全性上有很大缺陷,这也是C和C++的一大区别。还有运算符和运算优先级过多,不便于记忆,语法定义不严格,编程自由度大,对新手不太友好。适用于系统底层, 驱动, 嵌入式开发。
C#:用C# 开发应用软件可以大大缩短开发周期,同时可以利用原来除用户界面代码之外的C++代码,相比java,有更先进的语法体系、强大的周边。缺点:没有考虑代码量。
C++:可扩展性、高效简洁快速、可移植性、面向对象的特性、强大而灵活的表达能力和不输于C的效率、支持硬件开发、程序模块间的关系更为简单,程序模块的独立性、数据的安全性就有了良好的保障、通过继承与多态性,可以大大提高程序的可重用性,使得软件的开发和维护都更为方便,适用于游戏开发, 大规模, 高性能, 分布式要求的程序开发。
Python的特点:
√优雅、明确、简单
√解释型语言√开发效率非常高√高级语言√可移植性√可扩展性√可嵌入性Python的不足之处:
√运行速度慢
√代码不能加密√多线程不能利用多CPU问题2. 简述解释型和编译型编程语言?
计算机是不能理解高级语言的,更不能直接执行高级语言,它只能理解机器语言,所以任何使用高级语言编写的程序若想被计算机运行,都必须将其转换成计算机语言。从而产生了两种转换方式:解释和编译,所以高级语言也分为了解释型语言和编译型语言。
(1)解释型语言的源代码不是直接翻译成机器语言,而是先翻译成中间代码,在程序运行的时候再由解释器把中间代码翻译成机器语言,解释型语言每执行一次就要翻译一次,效率比较低。比如Python、JavaScript、Perl、Shell等。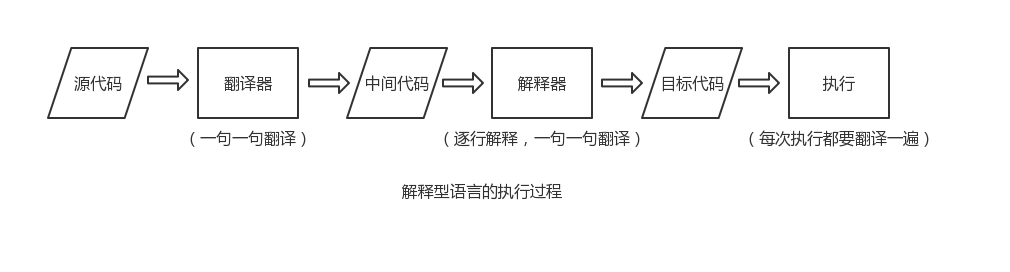
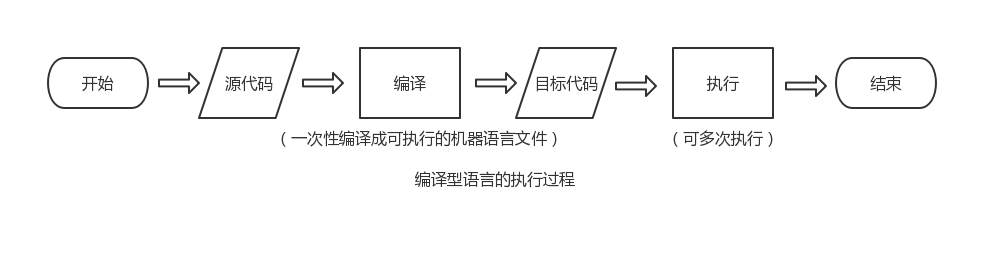
(2)编译型语言在程序运行之前需要一个专门的编译过程,把源代码编译成机器语言的文件,等程序运行时,不需要重新翻译,不管运行多少次,都可以直接使用编译的结果,程序执行效率高,但依赖编译器,跨平台性差些。比如C、C++、Delphi等。
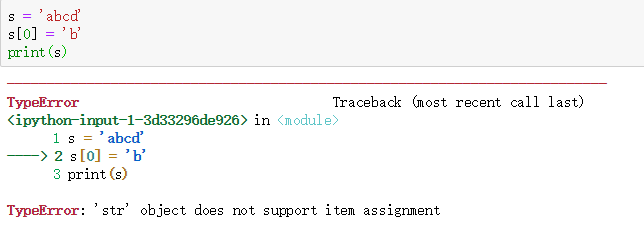
3. 代码中要修改不可变数据会出现什么问题抛出什么异常
报错,抛出TypeError异常。不可变数据类型包括 int、float、string(字符串)、tuple(元组)。可变数据类型包括 list(列表)、dict(字典)、set(集合)。
4. print 调用 Python 中底层的什么方法
在 python2 中,print 是一个命令;在 python3 中,print 是一个函数,print() 调用 sys.stdout.write() 实现,往控制台打印字符串。但是print() 跟 sys.stdout.write() 还是有点区别,print() 能自动换行,sys.stdout.write() 不能自动换行。print()能接收多个参数输出,sys.stdout.write() 只能接收一个参数。另外,sys.stdout.write() 只接收字符串格式的参数。
# python2中,两种方式print 'hello world'# hello worldprint('hello world')# hello world# python3中,一种方式print('hello world')# hello world 
5. 简述你对 input()函数的理解
6. Python解释器种类以及特点?
-
Cpython:默认是Cpython解释器,c语言实现
-
IPython:基于CPython之上的一个交互式解释器
-
Jpython:java实现,Python代码会先转化成Java字节码
-
PyPy:python实现的python解释器,pypy运行效率高
-
IronPython:c#实现
7. Python2 中 range 和 xrange 的区别
两者用法大致相同,不同的是 range 返回的结果是一个列表,而 xrange 返回的结果是一个生成器,range 是直接开辟一块内存空间来存放列表,xrange 则不会直接生成一个列表,而是每次调用返回其中的一个值,只有在使用的时候才会开辟内存空间,是边循环边使用,所以当列表很长时,xrange 性能比 range 好。
>>> print(type(range(10)))>>> print(type(xrange(10))) >>> print(range(10))[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]>>> print(xrange(10))xrange(10)
8. 位和字节的关系?
8 位(bit)= 1 字节(Byte)
位 (b) => 二进制位(0 或 1),是最小数据单位。
字节 (B) => 存储空间的基本计量单位,基本上1byte 存1个英文字母,2个byte存一个汉字。
9. b、B、KB、MB、GB 的关系?
1 GB = 1024 MB
1 MB = 1024 KB1 KB = 1024 B1 B = 8 bit10. 请至少列举5个 PEP8 规范(越多越好)
-
缩进:使用4个空格的缩进,不要使用制表符(Tab键),禁止空格与Tab键混用。
-
换行:折行以确保其不会超过79个字符。这有助于小显示器用户阅读,也可以让大显示器能并排显示几个代码文件。
-
空行:使用空行分隔函数和类,以及函数内的大块代码。顶级函数间空2行,类的方法之间空1行,同一函数内的逻辑块之间空1行,文件结尾空一行。
-
注释:如果可能,注释独占一行。避免逐行添加注释,避免没有一个注释。
-
空格:运算符周围和逗号后面使用空格,但是括号里侧不加空格,如:a = f(1, 2) + g(3, 4)。
-
导入格式:每个导入独占一行,导入放在文件顶部,位于模块注释和文档字符串之后,模块全局变量和常量之前。导入应该按照从最通用到最不通用的顺序分组(标准库 -> 第三方库 -> 自定义库),每种分组中, 应该根据每个模块的完整包路径按字典序排序,忽略大小写。不要使用 from xxx import * 这种语法。
-
变量命名:尽可能的使用有意义的变量名,词能达意。下划线命名法和驼峰命名法。包名、模块名、函数名、方法、普通变量名全部使用小写,单词间用下划线连接。类名、异常名使用 首字母大写(CapWords ) 的方式, 异常名结尾加
Error或Wraning后缀。自定义的变量名、函数名不能和标准库中的函数名重名。 -
私有变量:小写和一个前导下划线(如:_value)。
-
内置变量:小写,两个前导下划线和两个后置下划线(如:__init__)。
11. python递归的最大层数?递归函数停止的条件
可以通过 sys.setrecursionlimit() 进行设置,但是一般默认不会超过3925-3929这个范围。递归函数停止的条件一般定义在递归函数内部,在递归调用前要做一个条件判断,根据判断的结果选择是继续调用自身,还是 return 返回,停止递归。递归函数停止的条件:
- 判断递归的次数是否达到某一限定值
- 判断运算的结果是否达到某个范围等,根据设计的目的来选择
12. ASCII、Unicode、UTF-8、GBK的区别?
-
ASCII:在计算机内部,所有信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此8个二进制位可以组合出256种状态,这被称为字节(byte)。ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。它的范围基本只有英文字母、数字和一些特殊符号 。
-
Unicode:又称万国码,将世界上所有的符号都纳入其中,每一种符号都给予独一无二的编码,防止乱码。
-
UTF-8:变长码,UTF-8是在互联网中使用最多的对Unicode的实现方式。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
-
GBK:GBK编码是对GB2312的扩展,完全兼容GB2312,GB2312是对ASCII码的中文扩展。GBK全称《汉字内码扩展规范》,使用双字节码,是用来编码汉字的。
13. 字节码和机器码的区别?
字节码:一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
机器码:是计算机可以直接执行,并且执行速度最快的代码。
14. 三元运算规则以及应用场景?
三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值。三元运算符的功能与 if...else 流程语句一致,它在一行中书写,代码非常精炼,执行效率更高。
格式:[on_true] if [expression] else [on_false](res = 值1 if 条件 else 值2)
15. 列举 Python2和Python3的区别?
-
print 语句:在 python2 中 print 是一个命令语句,不论想输出什么,直接放到 print 关键字后面即可,如:print "内容";在 python3 中,print() 是一个函数,像其他函数一样,print() 需要你将要输出的东西作为参数传给它,如:print("内容")。
-
Unicode 字符串:在 python2 中有两种字符串类型,Unicode 字符串和非 Unicode 字符串;在 python3 中只有一种类型,Unicode 字符串。因为 python2 中使用 ASCII 码作为默认编码方式导致字符串有两种类型;python3 中默认 Unicode 编码。
-
input 语句:在 python2 中,分为 input() 和 raw_input(),input() 接收 int(整型)类型的数据,raw_input() 接收 str(字符串)类型的数据;在 python3 中,input() 是内建函数,不需要导入,input()接收的所有数据都是字符串类型。
-
整数:在 python2 中区分整型、长整型;在 python3 中统称为整型,可存超长数据。python2 中的 int(整型),在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647。在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807。python2 中的long(长整型),跟C语言不同,python的长整数没有指定位宽,即:python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。自从python2.2起,如果整数发生溢出,python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
-
在 python2 中,键入的任何不带小数的数字,将被视为整数的编程类型。比如5/2=2,解决方法:5.0/2.0=2.5;在 python3 中,整数除法变得更直观 5/2=2.5。